
如果你会下围棋,那么你一定已经知道了Master。从12月29日起,神秘高手Master在网络围棋对战平台横空出世,击败了各路棋坛职业选手,其中包括目前的中国围棋第一人柯洁。在今天对战聂卫平之前,Master已经53胜了,然而老聂也输了,人类最后的防线也被AI击破。
早在去年年初,AlphaGo已经通过4:1的比分向世人证明,AI的棋艺已经超越了人类,Master在棋力上只不过是AlphaGo的升级而已。考虑到机器深度学习的效率,半年时间内有如此的进步并非不可能。然而看过Master棋谱的人都知道,Master和AlphaGo可不是两个可以相提并论的AI。AlphaGo虽然赢了,但他赢的方式是人类式的,我们可以看懂他的棋;Master却不同——颠覆定式、频繁脱先、违背棋理,但是全人类就是没有一个人能够战胜它。这一次人类不仅仅是输了,而且连自己为什么输了都不能理解。
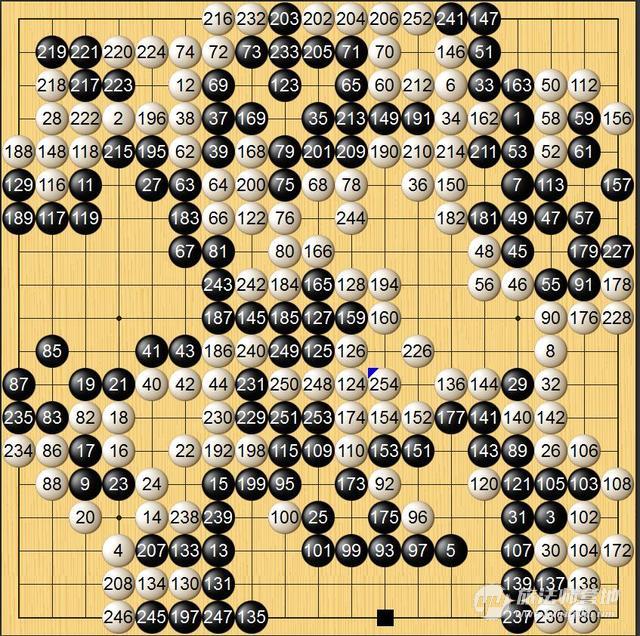
今天Master和聂老下的这盘
讲到这里,相信很多人非常好奇,这个Master到底是何方神圣?大家猜测最多的是:Master要么是AlphaGo本尊,要么是它的升级版。
此前有媒体称,谷歌公司的下DeepMind团队发文承认Master是AlphaGo 的升级版,还列出推特截图作为证据。不过,这条推特发布时间虽然是去年12月29号,但所附链接时间却是12月14号。此时Master还未横空出世。
因此,单凭这条信息不能推断Master就是AlphaGo。此外,谷歌方面也从未证实过。就目前而言,除了Master这个用户名以及注册地为韩国外,我们对Master一无所知。
不过,相比于AlphaGo实打实地与李世乭对弈,Master留了一手狠招:下快棋。
根据Master的规则,对弈双方要在30秒钟内做出反应。之前也有棋手提出更改对局用时,但都Master拒绝了。30秒一手的快棋,对精力和反应都是不小的考验,即使是柯洁、朴廷桓这样的年轻棋手,也有很多失误,严重影响对局质量。
Master和我们的顶尖高手下的都是30秒以下的快棋,我们跟它约30秒以上的棋它是不接受的,它这次来好像就是测试快棋的实力的。
可能是考虑到聂卫平已经64岁了,在今天下午的对战中,"Master"主动把对局用时调整成了1分钟一手。但这显然还是不够。
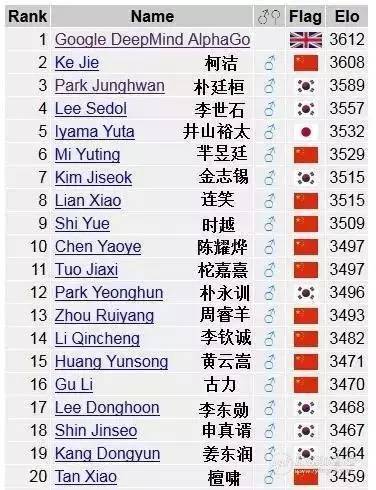
如今在世界围棋手排名中,AlphaGo雄踞第一,柯洁只能屈居第二
但本文要讲的不是这个。笔者对围棋的了解不深,只能说是略知一二,我相信本文的读者也不是冲着围棋棋艺研究读这篇文章的。我要说的是一个普遍的游戏设计问题:局部稳定性。
所谓局部稳定性是指,在一个游戏中,局部最优解能够诱导出全局最优解。比方说,在围棋中,当双方在一个区域内交锋时,在该区域内获得优势(包括实地和外势)对于整局棋来说是有利的。再比如说,在dota里面,双方对线时,杀对面一个英雄而己方英雄不被杀对全局来说也是有利的。类似的例子比比皆是,甚至可以说,局部稳定性是所有游戏的共性。然而,Master的棋术却颠覆了人类对围棋的稳定性的认识。如果要用一个词来形容Master的棋风,那就是全局观。对于人类棋手来说,全局观是一种较为缥缈的意识;我们总是说,获得外势也是一种收益行为,但是这种外势究竟能转化为多少实地、在未来的对局中又能产生多大影响,没有一个人可以给出精确的回答。但是Master不一样;在双方的交锋过程中,Master频繁地脱先(给没下过围棋的读者解释一下,脱先是指从当前战场区域中暂时脱离,转而在其它区域落子。这大概就好比dota里双方10个人在中路打团,结果你突然一个TP从中路飞到下路),这种对人类来说难以理解的行为是由Master对全局的宏观掌控计算得出的——在它的眼里,根本就没有什么局部的概念,一盘棋就是一个整体。而Master对人类的大胜,也体现出了围棋本身并非一个局部稳定的游戏。
解释完了这个概念,我们来分析一下为什么局部稳定性对于游戏来说是一个至关重要的性质。这涉及到另一个概念:学习成本/学习曲线。所谓学习成本,是指玩家在学习一款游戏时所耗费的时间精力;而学习曲线则是指不同的阶段玩家为了提升游戏水平而需要的学习成本。请想象一个坐标系,横轴是玩家水准,竖轴是时间投入,坐标系上绘出的曲线就是学习曲线。如果一个游戏简单易上手,那么它的学习曲线将会比较平缓;而对于一些难以上手的游戏,学习曲线就将会比较陡峭。关于学习曲线的理论还有更加深入的内容,比如学习曲线的起点、终点、拐点应当如何设置,限于本文所选的话题,就不再仔细论述了。
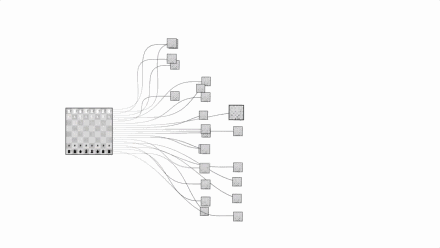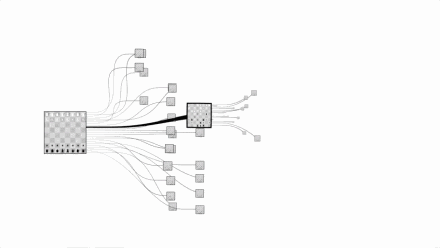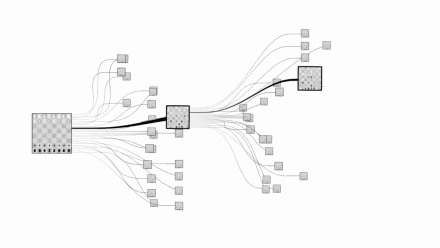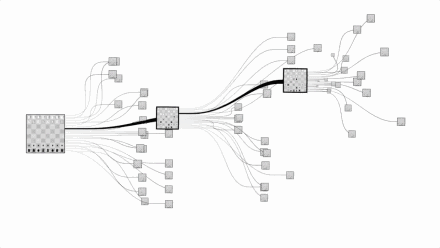
国际象棋复杂程度

围棋复杂程度
我们回到刚才的论题。一个游戏局部稳定,意味着这个游戏的学习曲线是平滑的。请试想一个新手玩家接触到一款游戏,他应该如何学习游戏的玩法?最符合常理的作法是遵循新手指南的要求,一步一步地了解这个游戏的各个机制。此时,玩家对游戏还没有一个整体的把握,他的抉择能力还不足以做出一些较为复杂的判断,从而他通常都只会考虑局部最优解。比方说,炉石玩家在最初接触游戏时,总是先考虑当前回合应该怎样做出最优的随从交换,当前回合的法力水晶怎样才能最优分配;war3玩家在最初接触游戏时,总是尽可能减少每一次战斗中己方部队的损耗,并尽可能地损伤对手的部队;围棋棋手在最初下棋时,总是做好每一块棋的死活,占据更多的实地。如果一个游戏是局部稳定的,也就是说,局部的操作的最佳结果一定是整局游戏的最佳结果,那么,玩家在这个过程中所学习到的内容就可以应用于未来的更加高阶的游戏对局中,从而他的水平的的确确在学习过程中得到了提高。而如果一个游戏是非稳定的,那么情况就会糟糕许多。比方说(这个例子很难举,因为非稳定的游戏都已经被市场淘汰掉了),我们设想一款moba游戏,英雄等级提升后HP、MP增加但攻击力降低——这意味着升级这个行为既可能是有利的也可能是有害的——那么,一个新手玩家在接触这个游戏时,如何知道他该不该占线升级?更极端地,对面一个残血英雄从你面前经过,你该不该随手一A把他杀死?由于游戏是非稳定的,这种抉择就很难合理地做出;除非玩家已经非常系统地理解了这个游戏,否则最优抉择将是无迹可寻的。这将会严重地破坏新手体验,从而这款游戏根本就不会有人玩。
XIXO今日推特
基于上述分析,在游戏设计过程中,我们总是希望自己所设计的游戏具有局部稳定性。然而,现在摆在我们面前的是这样一个问题:在设计一款游戏的时候,设计团队怎样才能确定当前的游戏机制是否是稳定的?在以往的经验中,我们是通过理论推算加上实测来解决这个问题的。一方面,我们保证游戏进程具有某种单向性,比如说dota里面我的胜利目标是拆对面的世界之树,而敌方世界之树的血量降低不会对我方产生任何不利影响,那么攻击世界之树这个局部最优解就肯定是全局最优解(这里顺便说一句,dota的英雄升级没有理论上的稳定性,因为英雄升级后复活时间加长,此外还有末日爸爸的等级炮——我认为,冰蛙重做等级炮就是为了降低这种不稳定性,使得提升等级总是玩家的局部&全局最优解);再比如,炉石里面的胜利目标是把对手的生命值打到0,而对手生命值降低对我没有不利影响(我知道你们要说熔核巨人;没错,熔核巨人的存在使得炉石不具有局部稳定性——与dota的例子相同,我认为暴雪削弱熔核正是为了消灭这种不稳定性),那么在对面空场的时候我用随从打对面的脸这个局部最优解就肯定是全局最优解。另一方面,当游戏的模型过于复杂以至于上述理论分析无法奏效时,我们进行实测,通过大量的测试找出最优打法,然后评估局部最优解是否总是全局最优的。
一直以来,我们认为这种评估方式是可靠的——毕竟我们用了这么久,还没有反例出现嘛。凡是我们认为是稳定的游戏机制,在实践操作中确实表现出了局部稳定性。然而,我们遇见了Master。围棋,这一项人类研究时间最长的智力竞技项目,这一个作为局部稳定性典范的例子,这一款被称为游戏设计榜样的抽象桌游,被Master证实为非局部稳定的。我们关于围棋的所有理论必须重写,因为我们曾经以为是最优解的下法根本就不是最优。然而这还不是全部。现在谁又有理由宣称,我们所熟悉的其它游戏的局部稳定的呢?说不定哪天,等AI能够玩dota了,我们会发现,死亡一指点天灾远程兵才是最优策略。而这对于游戏设计者来说实在是一种羞辱。