大地图设计可谓是所有SLG的命脉,它的优化也与玩家实机体验息息相关。只是受硬件、内容、技术等现实条件限制,不少开发者都很难找到一套合适的优化方法。
在这种情况下,同为SLG的《重返帝国》却显得有些不太一样。它不仅采用了操作量更高的自由行军设计,还引入了“千人同屏,万人观战”的攻城战设计,似乎完全不用担心大地图的优化问题。
在上周召开的IGDC国际游戏开发者大会上,《重返帝国》大地图基础架构负责人周元军从流量和性能两方面,分享了游戏大地图相关的优化经验,以及部分具体的处理措施。
以下是周元军的分享整理:(为照顾阅读体验,内容有所调整)
01 大地图设计存在哪些挑战
我们今天主要分享三个方面的内容。首先,我会简单介绍一下我们大地图的玩法特点和设计挑战,然后分别从流量和性能优化两个方面,讲一下我们是如何应对这些挑战的。

《重返帝国》支持自由行军和持续战斗。玩家可以任意拖动自己的部队,不需要走格子;战斗也是一个持续过程,在大地图上实时计算,玩家可以根据当前战况,选择继续进攻或者是撤退。
我们还支持无极缩放,允许玩家任意调整视野。像上面三幅图,最左边是地表层,玩家可以看到最详细的战场信息,玩家可以在这一层进行微操和走位;再往上缩放,就会进入战场层,在这里我们能看到整个战场整体的局势;而再往上,就会进入国家层,我们可以看到各个国家势力分布。联盟官员可以在国家层规划自己联盟的发展路线。
游戏的第四个特点则是超大规模团战。《重返帝国》鼓励团战,是一个赛季制的缩圈玩法游戏。玩家最开始诞生在最外圈的出生州,接着会以联盟为单位,向中间的资源州和最内圈的核心州进发。越往内圈,资源就越少,联盟之间的冲突自然也就越多。
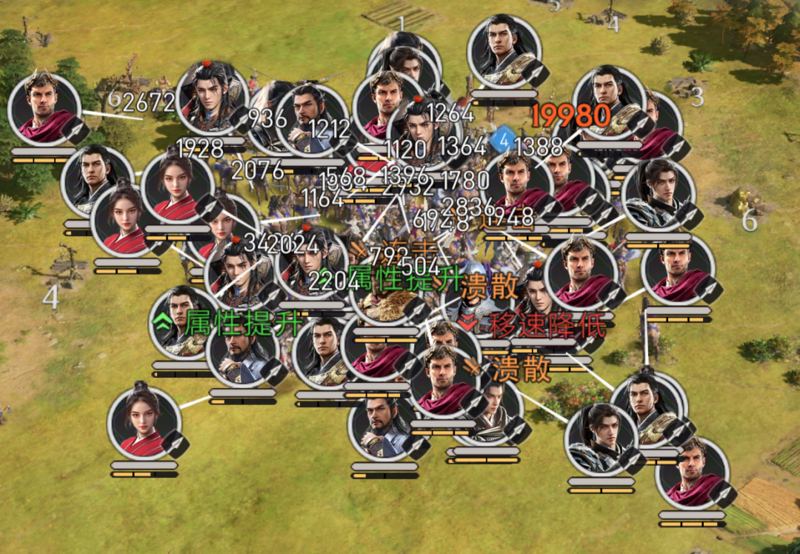
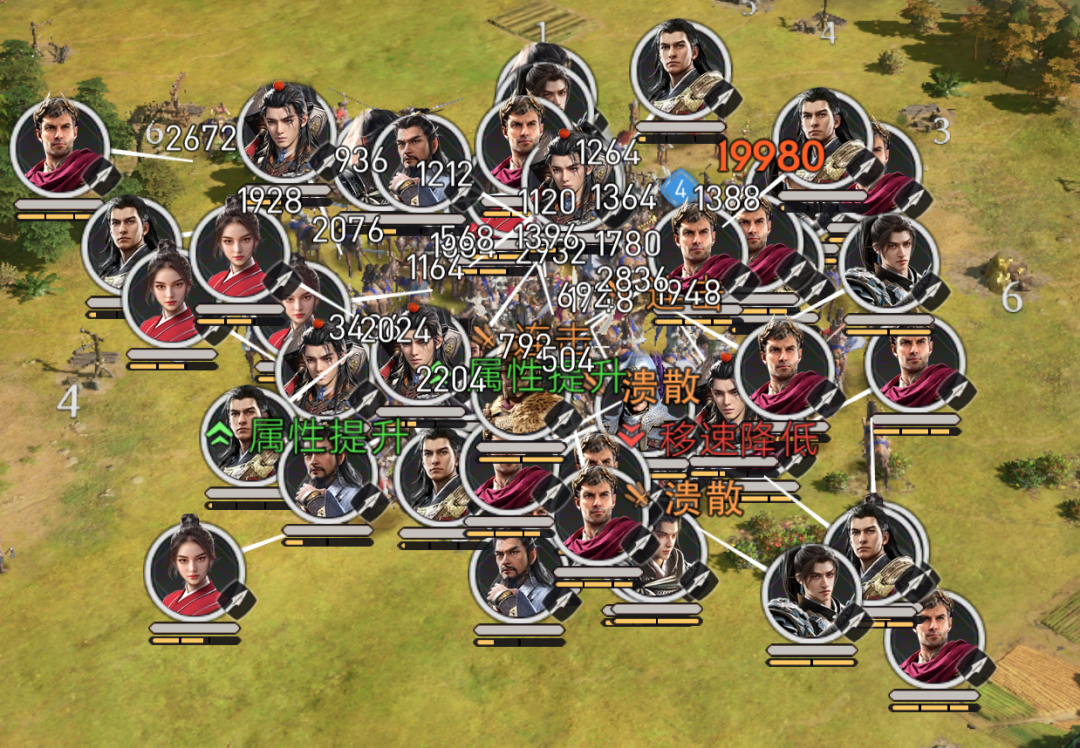
《重返帝国》玩家的最终目标,就是占领中间的皇城。通常会有3-4个联盟参与抢夺皇城,每个联盟有180个玩家,每个玩家又可以最多拖出5支部队,再加上一些攻城车、箭塔之类的,玩家视野范围内的战斗单位可以轻松达到上千。

玩家截图,来自网络
当然,这些玩法特点也带来了一些设计上的挑战。首先就是超大地图和超多对象。我们整个大地图是5000米*5000米的,分布着超过50万的可见对象。另外两个挑战就是千人同屏、万人观战,特别是刚才讲的皇城战,基本上全服所有玩家都会去围观。
02 流量优化
相对于服务器来说,客户端无论是在带宽资源还是计算资源上都更受限。如果我们把玩家视野内的所有战斗单位都直接发给客户端,客户端很难承受这么大的压力。因此我们一直在做流量优化,尽量减轻客户端的性能压力,给玩家更流畅的游戏体验。
我们做流量优化的整体思路主要分成两个部分,第一个是尽量降低向客户端同步对象的数量,第二个是尽量降低单个对象向客户端同步的流量。
在传统MMO游戏里面,“九宫格”是最常见的视野管理算法,它的优点在于原理和实现都非常简单,性能也非常高。
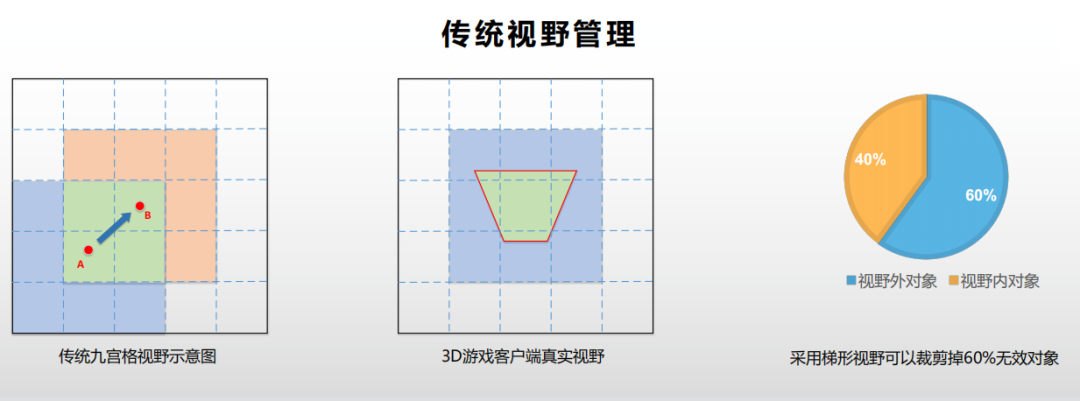
但是这个算法的缺点也非常明显。当玩家跨越格子的时候,比如说从A点跨越到B点,瞬间会有5个蓝色格子里的对象退出视野,5个桔红色格子的对象进入视野,这个瞬间就会出现一个流量洪峰。它可能会导致客户端卡顿,甚至是卡死,这是九宫格算法第一个缺点。
“九宫格”算法的第二个缺点是流量浪费。为了让玩家在格子的边缘能有完整的视野,客户端的可见区域不能大于4个格子的范围。并且在3D游戏里面,玩家真正的可见区域其实是一个梯形,比4个格子的范围更小。梯形范围外的同步对象,玩家是看不到的。通过面积来测算,我们也可以看到至少会有60%的同步对象客户端是看不到的。既然这些对象看不到,我们为什么要进行同步?
那么,《重返帝国》是怎么做视野管理的呢?我们也是基于格子来管理大地图上的对象。但是在更新视野时,会让客户端带上它的真实梯形视野范围,服务器会根据这个梯形范围来进行格子的初筛,这些格子内的对象包含了客户端可以看到的所有潜在对象。接着,我们会把这些对象和它的梯形视野范围进行精确匹配,仅向客户端同步它能看到的对象。
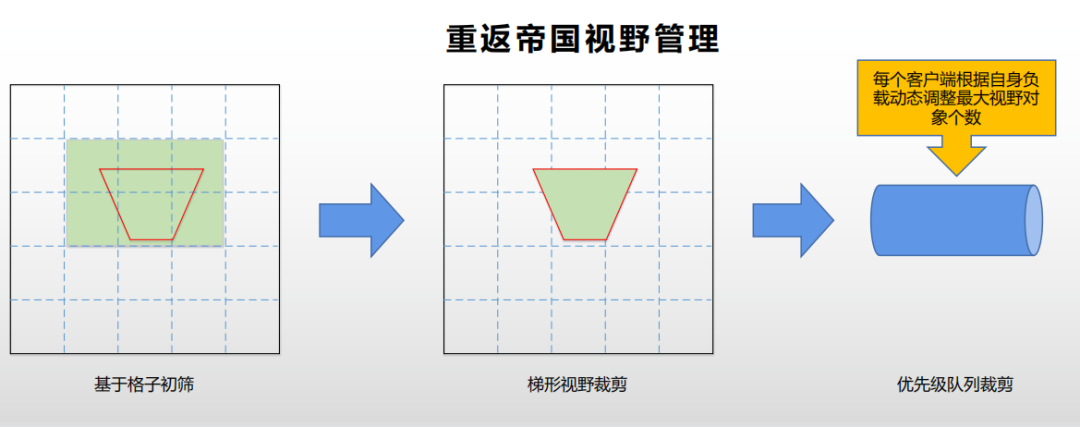
通过这两个优化,我们就可以保证《重返帝国》服务器向客户端同步的所有对象,都是客户端可见区域内的。
然而即使这样,当发生大规模团战时,我们的客户端压力依然很大。于是,我们又做了第三步优化,让客户端根据自身当前的实时负载,上报它能承载的最大对象数量,服务器会根据每个客户端的上报,进行优先级队列裁减,即只向客户端同步最重要、玩家最该看到的对象。
上面就是我们针对“尽量减少向客户端同步对象的数量”所做的一些优化。通过上面的优化,理论上只要卡顿,客户端就可以通过减少视野内对象数量来解决。但是为了保证玩家的游戏体验,我们也不能无限下调视野内对象数量,并且要尽量提高这个数量。所以,我们又做了第二个优化,尽量减少每个对象向客户端同步的流量。单个对象产生的流量主要来自对象属性同步和技能事件同步,下面我们会针对这两个流量大头,讲一下我们是如何优化的。
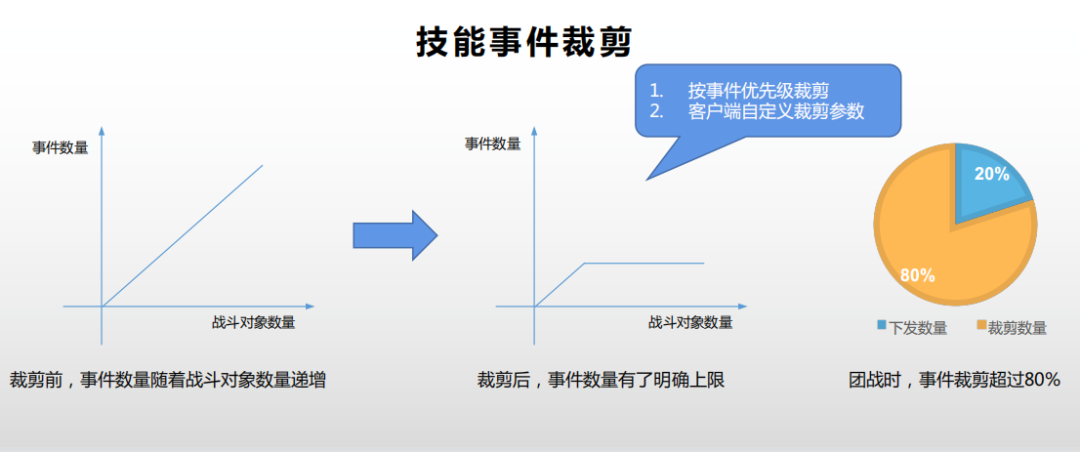
首先我们来看一下技能事件同步。技能事件主要用于跳字和特效表现。当它们超过一定数量之后,我们再向客户端同步相关内容,并不会继续提升玩家的体验。所以我们限定了一段时间内,向客户端同步的事件数量上限。目前《重返帝国》技能事件裁减的默认配置是每0.5秒最多向客户端同步50个事件,客户端可以根据自身负载动态调整这个参数。服务器会针对每个客户端,计算事件的优先级,然后按事件优先级进行裁剪。比如玩家自己的战斗事件优先级最高,不能裁剪;一些稀有技能的优先级也比较高,要优先发送,等等。在我们外网的真实统计数据中,在默认裁剪参数下,我们可以裁剪掉超过80%的技能事件,这有效缓解了客户端的性能和发热等问题。
下面我们来讲一下属性同步。对象属性同步产生的流量占据了客户端全部流量的绝对大头,属性同步也是每个游戏框架必须要解决的问题。我们认为,属性同步主要要解决两个问题——哪些属性需要同步给客户端?当属性发生变化时,怎么将这些变化同步给客户端?针对这两个问题,我们自研了一套基于自动代码生成和标签的树形属性同步系统。
《重返帝国》属性系统主要具有以下特点:第一个是字段级增量同步,也就是当属性发生变化时,服务器只会向客户端同步变化数据。第二个是按需同步,即服务器向客户端同步的所有属性都是客户端当前需要的,客户端不需要的,不会同步。第三个是零开发成本,就是我们这套属性同步系统是自动完成的,不需要任何额外的开发。
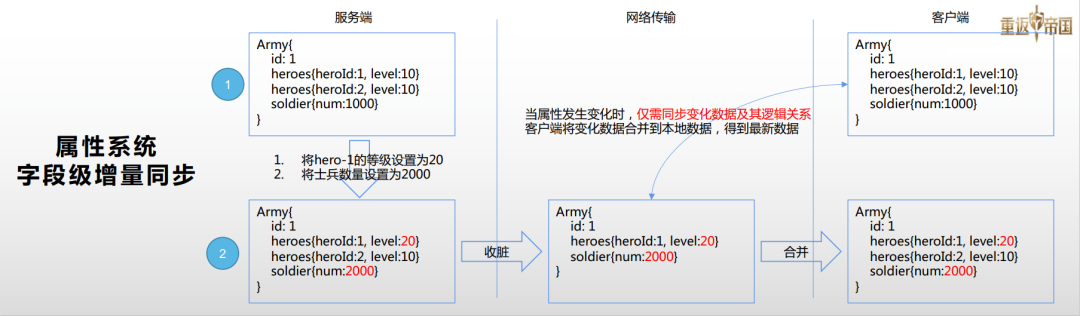
我们先聊聊字段级增量同步。上图是一个示例,假设服务器和客户端在1时刻都有一个Army对象,它的属性是一致的。因为某些原因,服务器将hero-1的等级设置成20,将士兵数量设置成2000,我们该怎么将这个变化数据同步给客户端呢?
我们属性系统有一个收脏函数,它会把这些修改过的数据收集到协议态。这个函数仅仅会收集变化的数据,还有它的逻辑关系,我们仅会向客户端同步这部分变化数据。当客户端收到这个增量数据之后,它会和本地的数据合并,从而得到最新的属性数据。
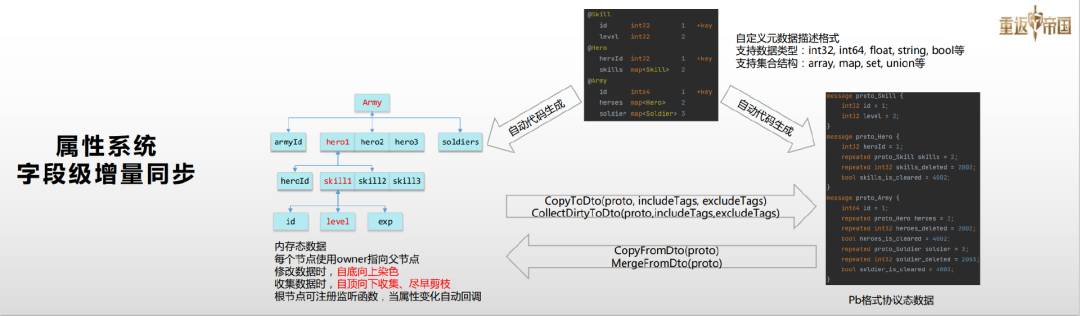
为了做到字段级增量同步,我们自定义了一套元数据描述格式。目前我们这套元数据描述格式支持int32、int64等常见的数据类型,也支持array,map,set等集合结构。
根据这套元数据,我们会通过自动代码生成工具生成两份代码文件,一份是内存态数据,这份数据会提供常见的get/set接口,还有集合操作接口,我们的开发同学基本上只会使用这份内存态数据。另外一份是协议态数据,我们目前采用了ProtoBuff,这个是可以进行插件化的替换。内存态的数据和协议态的数据之间存在两组转换接口,首先是由内存态向协议态的转换,我们可以将内存态的数据全量拷贝到协议态,也可以将内存态的脏数据收集到协议态。从协议态到内存态的转换同样有两个接口,一个是拷贝,也就是从协议态的数据完整创立一份内存态的数据;另一个是合并,也就是说将增量的数据合并到内存态数据。
当修改内存态数据时,我们会进行自底向上的染色,当我们收集脏数据时会自顶向下收集,尽早剪枝。我们的根节点可以注册监听函数,当有变化时,我们的监听函数就会被调用,然后我们可以在这个函数里面去做一些操作,比如说同步客户端、存盘等,从而实现全自动化的属性同步。
上面就是我们属性系统实现的方式和字段级增长同步的相关描述。接着我们还看下另外一个问题,就是按需同步。我们希望向客户端同步的所有对象,都是客户端当前所需要的。

按需同步,我觉得主要有三个场景。第一个就是数据的需求方不同。比如说一份玩家数据,有些可能仅仅是玩家本人需要,有些可能需要同步给队友,有些可能需要同步给视野内其他的一些观察者。我们是不是可以做到针对不同的数据需求方同步不同的数据?
第二个场景是数据的需求时机不同。通常玩家的属性数据会非常大,但是某些数据或者大部分数据可能仅仅是在某些特定的场景,或者当玩家打开某些特定界面时才需要。这时候我们能不能做到仅当玩家在这些场景之内的时候,才同步这部分属性数据?
第三个是LOD同步,就是一个对象离我们越远,我们可以看到他的细节就越少,我们是不是可以同步更少的属性数据。这就是我们按需同步的三个问题。

我们是通过业务层自定义标签来实现按需同步的。大家可以看到中间的属性定义格式,我们可以看到最后一列有非常多的+layer1,+layer2等,这就是我们的一些标签。这些标签是由业务层来定义的,它可以加在基础字段上,也可以加在结构体上,并且可以进行任意组合。
我们框架层并不解释这些标签,标签都是由业务层定义并且管理。框架层仅仅是提供了两组接口,一个是拷贝接口,用于将内存态数据完整拷贝到协议态;另一个是收脏接口,用于将最近修改数据收集到协议态。这两组接口可以指定黑名单标签和白名单标签。当我们指定黑名单标签调用这两组函数时,如果某个字段有这个标签,我们就会直接跳过这个字段,不对它进行打包或者收脏。如果指定了白名单标签,我们就只会打包或者收脏包含这部分标签的字段。当业务层需要对内存态数据进行打包或者收脏时,需要向框架层传递黑名单标签和白名单标签。
这种实现方式的第一个特点是灵活性高,可以适配各种场景。第二个是职责清晰,开发层和框架层的分界是非常明确的,这样相关的开发成本和理解成本都是非常低的。这是我们按需同步实现的一个简单描述。

下面我们以无极缩放为例,讲一下我们是如何使用标签实现按需同步的。我们用三个圆表示一个对象的完整数据。假设在无极缩放第一层我们需要完整的三部分数据,第二层需要两部分数据,第三部分仅仅需要最核心的一部分数据,我们会怎么去做?
我们首先需要定义三个标签, +layer1表示仅第一层需要的属性数据, +layer2表示仅第二层需要的属性数据, +layer3表示仅第三层需要的属性数据。在定义对象属性时,可以针对每个属性在无极缩放中需要同步的层级,加上三种标签。当我们打包第一层属性数据的时候,我们可以把+layer1:2:3都设上,我们就可以打包出来一个完整的数据。当我们打包第二层的时候只需要设置+layer2:3,这样我们可以打包出中间的两部分数据。当我们在第三层的时候只需要设置+layer3,这样就可以获取无极缩放三个层次需要的不同对象数据。在收脏的时候,我们也可以根据玩家在哪一层看到这个对象去指定标签来收脏。比如当你在第三层看到这个对象的时候,你只会收到这个对象第三层数据的变化数据。
当我们向下缩放视野时,比如说我们从第三层缩放到第二层,并且这个对象一直在玩家视野内,我们向客户端同步的并不是这个第二层的完整数据,而仅会向客户端同步第二层特有的数据。当客户端收到这部分数据时,它会和它本地的数据进行合并,从而获得一个全量的第二层数据。通过这种方式,我们也是做到了没有任何重复属性的同步。这是我们属性系统在无极缩放上的一个示例。

下面我们来看一下属性系统在存盘上的应用,我们使用了腾讯自研的KV数据库tcaplus来进行实时存盘。DB和客户端有一个区别,就是DB没有办法进行实时的数据合并。这时候我们的做法就是将玩家的DB数据定义分成两个部分,一个叫做fullData,另一个叫做deltaData。默认当玩家属性发生变化时,我们仅仅会把这部分变化数据收集到deltaData,然后仅仅会对deltaData进行存盘。
当deltaData达到一定大小或者是达到一定条件时,我们会把它合并到全量数据。我们去拉取这个玩家数据的时候,也在同时拉取他的fullData和deltaData,然后我们会根据fullData创建一个内存对象,再将deltaData合并进来,从而获得最新的数据。通过这种方式,我们的本质就是自动分离了热点数据和非热点数据。

上图是我对一个300人在线服务器的存盘数据统计。300人在线每分钟大概是增量存盘了1300多次,全量存盘仅有10次,增量存盘的大小是4K左右,全量存盘的大小大概是在100K+。在这份数据里面,我们最近修改的数据仅仅占全量数据的4%左右,并且随着我们玩家全量数据的增大,最近修改数据的占比会越来越小。就是这份数据如果我们全部采用全量存盘的话,相对于现在我们这个方案,我们的流量节约大概是20多倍。
属性系统除了前面我们提到的字段级增量同步、按需同步等优势,它还有一个好处就是能够提升开发效率。属性系统借助自动生成代码,使得上面提到的所有过程都是全自动完成的,不需要我们的开发同学再做任何开发。

目前,《重返帝国》项目基本上没有手写的notify协议。我们使用的属性系统一共定义了超过5000条的属性,超过1300多个结构体,一共有54种不同场景的通用标签。通过这些原数据,我们一共生成了150万行代码、1300多个文件。
虽然我们生成的代码比较多,但是这部分生成代码并不会增加我们整个系统的复杂度。因为这1300多行代码,它的结构是完全统一的,我们开发同学只需要看懂其中一个文件,就可以推出其他1300多个是什么格式。
在我们《重返帝国》服务器团队里面,我们也是大量使用了自动代码生成来解决一些重复性的工作。
03 大地图性能优化
大地图是我们整个游戏的核心,同时也是逻辑最复杂、性能压力最大的模块。首先是性能压力问题,我们使用单核肯定不能承载这么大的压力,因此我们整体的方案就是利用可控的多核计算资源。方案选型时,我们希望同时满足两点要求。首先必须要抗住大地图性能压力,其次要充分考虑开发效率,实现复杂度等因素,把多线程、多进程的负面影响降到最低。

常见的大地图性能优化方案有两个。第一个是按空间划分,即Zoning,也就是我们常听说的无缝大地图。它将整个地图分割成不同的区域,这些区域可以单独调度在不同的线程或者进程,甚至这些区域的边界也可以根据它的负载进行动态调整。这个方案的优点就是拆分效果会比较好,理论上是可以支持无限大的地图,但是它的缺点也非常明显——它是一个全异步的编程范式,开发难度会比较高,开发效率会比较低。
第二个是按逻辑划分,即Offloading,就是将一些相对独立的功能进行拆分到单独线程。它的优点就是实现简单,开发效率高,缺点就是整个大地图的承载还是有上限的。综合考虑开发效率和成本问题后,我们整体上采用了Offloading方案。
我们做的第一件事情就是旁路线程拆分。我们把一些性能热点,并且功能相对独立的模块拆分成了单独的一些线程。
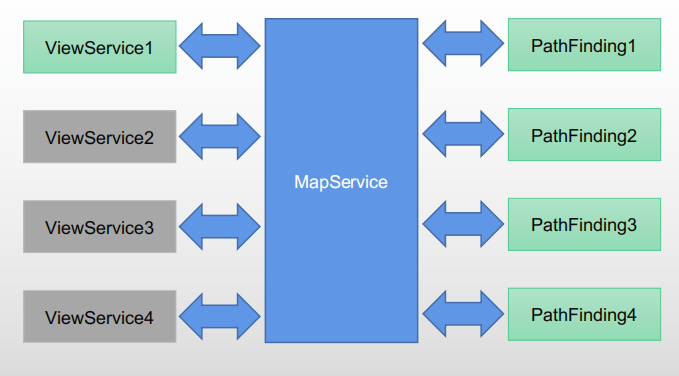
我们拆分的两个经典线程,第一个是视野线程,第二个是寻路线程。目前我们一个地图实例是可以支持配置多个视野线程的,但是我们压测下来发现,一个地图实例配置一个视野线程就可以承载我们的压力,所以目前我们只开了一个。第二个拆分出来的线程是寻路线程,我们开了4个寻路线程,我们对移动进行了异步化改造,所有的寻路请求都是通过异步化请求来实现。
视野管理是一个计算密集型的服务。大部分MMO游戏之所以采用九宫格做视野管理,一个很大的因素就是因为它的性能比较高。但是它也存在刚才说的两个缺点,流量浪费和流量洪峰。我们将视野管理拆分成独立线程之后,性能就不在是我们的瓶颈,所以我们可以针对每个玩家做精确视野裁减,优先级队列裁减和技能事件裁减。除此之外,我们还做了服务器草丛视野,隐身技能等视野相关的特有玩法。
第二个是寻路服务。寻路在任何游戏里面,都是一个性能瓶颈,虽然现在寻路库和寻路算法比较多,但是它们在复杂地形下长距离寻路的上限是非常低的,通常只有几百TPS,这肯定不能满足我们的需求。常规的一些做法可能是要么降低寻路品质,要么就是优化性能,但这些办法成本都比较高。而我们把寻路拆分单独线程之后,寻路也不再是我们的性能瓶颈,我们可以开最高的寻路品质,甚至我们还有一些算力的余力,去做一些寻路的后期效果优化。
上面就是我们对功能相对独立的性能热点模块的优化方案。然而,还有一些性能热点模块,他们和大地图的逻辑耦合是非常严重的,这部分模块很难拆分成单独的线程。对于这部分的性能热点,我们采取的方式是结构化并发。我们是通过并行定时器实现有线并发的。
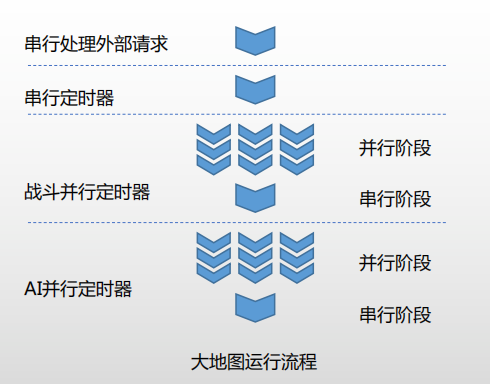
我们整个大地图的处理流程,首先是我们会串行处理外部的请求,然后串行处理定时器,然后按照类型分别处理并行定时器。我们整个并行定时器主要分成并行和串行两个阶段。并行阶段的任务,我们是分发到多个线程去执行的,在并行阶段执行完成之后,我们会进行一个串行的收尾阶段。目前我们使用结构化并发解决的性能热点有战斗和AI。通过并行定时器,我们就把多线程的范围限定在了一个处理函数,我们的开发同学只需要保证这个处理函数之间没有资源竞争,也就可以保证整个大地图的线程安全。
第三个方案则是视野投射。我们大地图上有非常多的封闭区域。这些封闭区域更类似于一个副本玩法,但是策划为了方便玩家观战,也为了让大地图显得更热闹一些,希望我们这些中立战场能开在大地图上,能在大地图上进行实时的观战和操作。

我们目前中立战场封闭区域大概有27个,每周定时开放,每次开放30分钟,每个战场可以有80个玩家参与,每个玩家可以最多参与2支部队。这样我们在中立战场开放时,整个大地图上的战斗单位可以达到上万个,超出了我们整个大地图的承载上限。对于这种需求,我们服务器的做法还是通过副本来实现这些中立战场,但是将这些副本的视野注册到我们大地图上。通过这种方式,首先是解决了我们这个特性的性能热点。第二个也使我们大地图上的逻辑更加干净。
以上便是《重返帝国》优化大地图性能的一些方式。总的来说,在同时考虑开发效率和性能承载的基础上,我们选择了线程拆分、结构化并发和视野投射三种方式。谢谢大家!