
更宏大的战斗场面,一直是很多传统MMO和SLG产品开发者追求的目标。
千人同屏,则是这个目标的缩影。例如下面视频中,腾讯《重返帝国》在复原大规模战争场面、拉高游戏策略爽度同时,也在思考如何向下兼容,从而保证玩家们战斗时的流畅体验。

比如最近,腾讯天美T2工作室户端组主程序肖健,以及引擎负责人侯仓健在全球游戏开发者大会(GDC)上,分享了使用Unity DOTS技术在《重返帝国》实现「千人同屏实时战斗」的相关思考和实践经验。
GDC对于非赞助类主题演讲的要求一向比较苛刻,往往会提前半年面向全球游戏开发者征集提案,由组委会层层筛选评比最终确认。包括重返帝国这一技术分享在内,腾讯天美工作室群在此次GDC共入围了4项非赞助主题演讲,意味着天美在游戏领域的多项技术探索获得了行业的广泛认可。
演讲重点内容如下:
《重返帝国》是一款全3D的SLG手游,游戏场景规模宏大,经常会出现超过1000个士兵一起战斗的场景。
在有限的移动设备性能上,如何同时兼顾性能与品质?团队在尝试过C#、C++以及DOTS等多种技术方案的选型与研究后,最终选择了Unity DOTS。
Unity DOTS对于团队可以说是一次敢为人先的选择,当时市面上并没有比较知名的使用这项技术的游戏项目,所以这项技术最后呈现出来的效果其实是没有太多参考的。
其次,当时DOTS是处于一个比较初期的版本,Unity官方还在不停的修改和完善,这意味着团队享受不到新的features,甚至可能需要处理一些潜在的隐患,这对团队来说是不小的挑战。01 实战分享
团队一方面与Unity官方保持密切的合作与交流,另一方面经过多次的技术迭代与优化,最终在《重返帝国》项目上取得了很好的实践效果,在移动设备上为玩家呈现了极高品质的视觉效果。同时团队也积累了一套行之有效的方法论,以下总结了几点分享给大家。
1.Job数据依赖分析与优化,提升整个系统的并发性
2.将部分ECS System的Job与非ECS逻辑并行,充分发挥多核
3.逻辑数据显示分离,提升chunk内存利用率,减少资源加载带来的卡顿
4.针对System进行逻辑降频,保证效果同时也提升性能
当我们完成了整体的框架设计和核心的实现后,在进行性能分析的时候发现Job的并发性并不高,且worker存在大量的idle状态,导致系统的整体耗时偏高。
为此,我们专门开发了静态分析工具辅助我们找出System之间的读写冲突与依赖,通过数据拆分、数据备份来解决冲突,让耗时较高的Job能够并行。

数据依赖静态分析工具
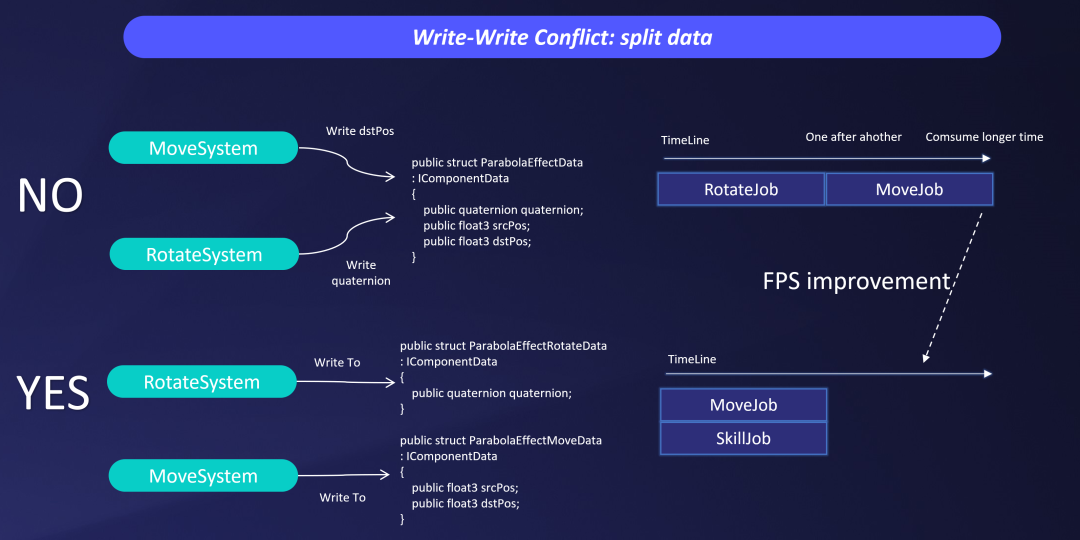
数据拆分解决写入冲突
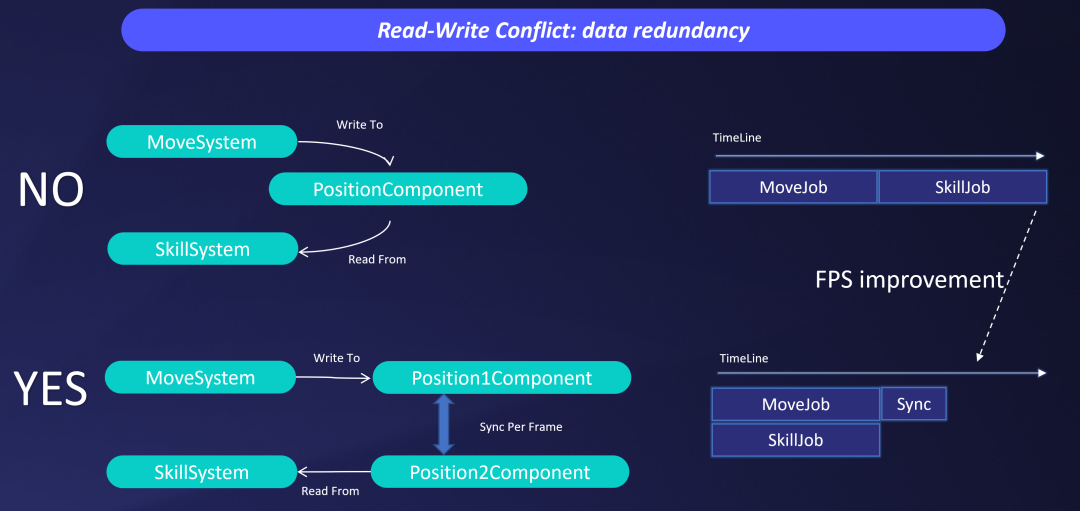
数据备份解决读写冲突
基于工具的分析,我们不断的细化和调整,解决了数据的冲突依赖,显著提高了Job的并发性,最终达到了我们相对满意的并行效果。

数据依赖优化后Job的并发执行
之后,我们还将System按照功能进一步的细化拆分,把一部分Job的执行提前到与非ECS代码逻辑并行,进一步从整体上提高了我们的游戏帧率。
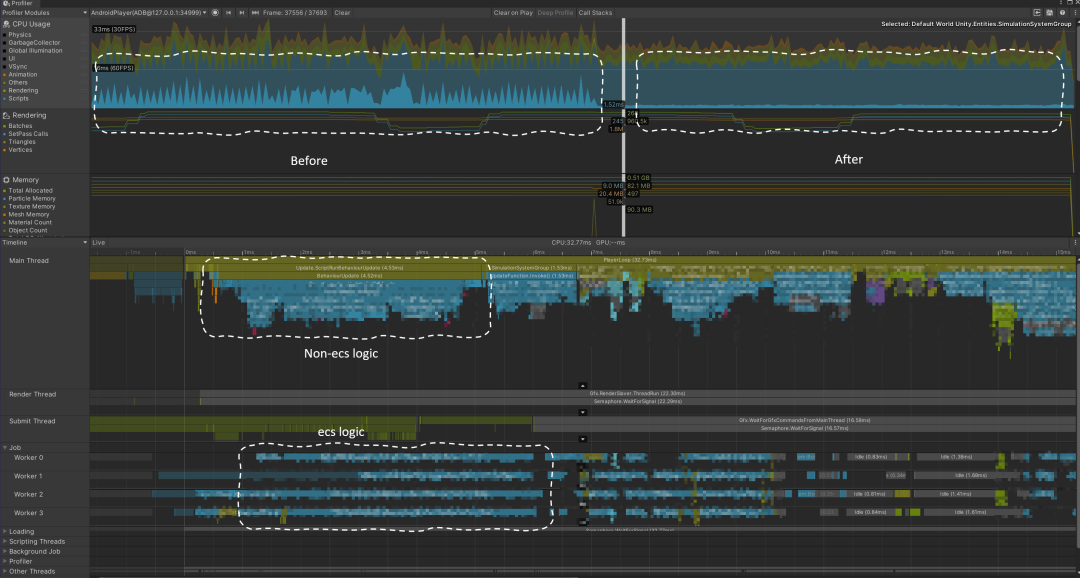
ECS Job与非ECS逻辑并行
在进行了Job并行性优化之后,我们发现在大地图上拖动时存在由于Entity资源同步加载导致的一些耗时峰刺,这对玩家来说是体验上的损失。
所以我们针对Entity,使用逻辑与显示分离,一方面让资源可以异步加载减少卡顿,另一方面也提升了单个chunk的内存利用率减少CPU的cache missing。

逻辑显示分离-资源异步加载
最后,我们在不影响效果的前提下,针对部分System进行逻辑降频与错帧(如移动逻辑计算相关的System降到12帧、耗时较高的MoveJob与AnimatorJob错帧执行),让整体的耗时更加平滑,并且有效的降低了游戏的功耗。
02 性能优化
当时我们使用的是 Unity2019版本,Hybrid Render V1 版本,为了能更顺利的将DOTS适配到我们的项目中,我们也在原始框架的基础上,在资产与渲染方面也进行了大量的按需开发。
我们在接入 DOTS 技术栈时,主要面临了以下3个问题:
1.资源兼容性:因为在接入时已经处于项目中期,很多游戏资产及对应的生产流水线已经成型,所以如何将已有游戏资产转变成可在 DOTS 技术栈中运行的资产,是我们需要解决的问题。
2.逻辑阶段的基础开销过大:可能会导致千人同屏场景出现时出现卡顿。
3.渲染阶段无法修改自定义的材质属性:因为我们对于战斗场景的还原重度依赖 GPU Instancing 技术,所以需要很多自定义的材质属性可以在运行时被复写。
于是,我们针对以上问题逐个研究核心痛点,找到了适合我们项目的解决方案。
在资源兼容性方面,在综合评估了各种方案之后,我们决定实现一套自己的序列化和反序列化流程。
我们的方案分为离线和运行时两个阶段:
离线时,我们将游戏中各类资产对应的prefab拆分成二进制文件和引用到的资源文件;
运行时,我们创建了一个“deserialize world”,用来把离线时生成的二进制文件和资源文件反序列化,生成entity。
当entity生成好后,我们再把它们移入default world进行运行。这样我们既可以在资产制作阶段使用我们熟悉的prefab,也可以减少运行时的转换时间。

资产Entity实例化
对于HybridRenderV1在逻辑阶段的开销过大,我们定位到了核心的瓶颈是主线程阻塞。比如整个生成合批信息的过程都是放在主线程中进行的,这个过程有很大的优化空间。
我们的优化方向就是多线程化,充分利用移动端的多核优势。其实在生成合批信息时,不同的RenderMesh一定对应不同的batch,任务本身具有可多线程化的特性。
所以如下图所示,我们分配了一个较大的缓存数组,数组的大小与线程数量和RenderMesh数量相关。多个线程并行完成对含有RenderMesh的Chunk进行筛选,并填入缓存数组的指定位置。因为在缓存数组中,每个线程都有自己的写入空间,所以多线程并行时,不会产生数据写入冲突。

多线程RenderMesh Batch
我们还对游戏中LOD的结构进行了优化。我们游戏中的模型一般有4层LOD,在转换成entity后,将会有6个相关的entities生成。
过多的entity不仅浪费内存,同时也会导致很多冗余计算(比如同步位置信息),而根据LOD的特点,我们可以只记录单个LOD的信息,在渲染时按需替换成应当显示的LOD Mesh即可,这样我们就可以把原本的4个LOD网格当做一个单独的网格来对待。
同时,我们也将LOD Group节点和Root节点进行了合并,Entity的数量也从原来的6个下降到2个,性能也有了提升。
这种方式带来的一个额外好处是当我们更高层级的LOD还未加载完成或渲染压力过大时,我们可以只加载低层级的LOD模型来显示。
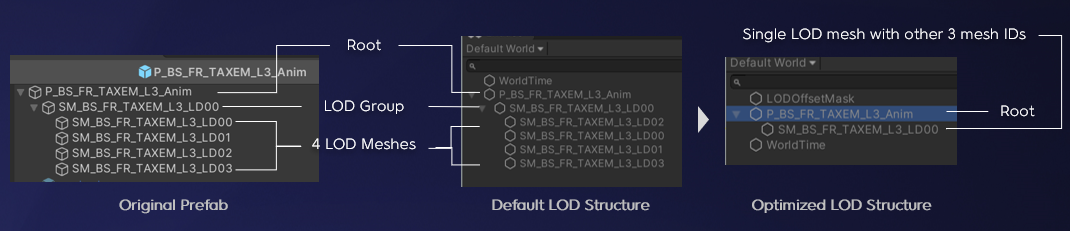
LOD结构优化
为了在C#中更改材质的Instance属性,我们定义一个和Instance属性完全匹配的IComponentData Struct,在数据对齐方面,我们遵循std140内存数据对齐原则。如下图所示
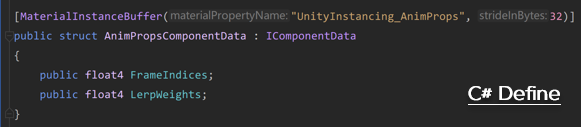
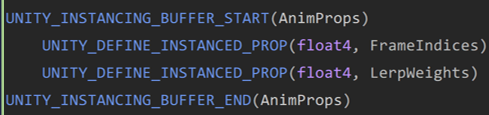
Instance属性对齐
在渲染运行时,我们根据entities的数量预先分配一块大的缓存,之后利用多线程把各个可见的entity的InstanceParam数据复制到Buffer中的指定位置。最后将整个缓存直接提交至GPU,我们就可以按照传统的GPU Instance方式来使用缓存中的数据了。
在有了RenderMesh上的材质信息和mesh数据之后,我们的InstanceBuffer也组织好了,这样通过调用Unity的DrawMeshInstanced接口就可以进行渲染了。

Instance Data Buffer
以上都是团队在实践中不断迭代总结出来的宝贵经验,希望能对那些同样想使用Unity DOTS技术的团队能有所启发。